AI models and machine learning algorithms are taking the world by storm. This includes the financial sector. McKinsey estimates AI could add $1 trillion of value to global banking alone!
If you are in the financial sector, you could benefit greatly from leveraging AI and ML in fintech offerings you may have. AI technologies are helping banks and financial institutions provide seamless, personalized services to millions of customers and play a massive role in fraud detection and prevention, real-time decisions, and internal workflow automation.
However, whether you are a startup or an established fintech enterprise, implementing AI algorithms does carry certain risks with regard to regulatory compliance in areas like security and data handling. Mistakes could be costly in terms of fines, as well as loss of brand reputation.
In such a high-stakes industry, having the right team with extensive knowledge of specific areas, such as the fintech sector, is crucial.
With outsourcing and staff augmentation partners like Trio, who specialize in fintech, allowing us to keep our dedicated fintech developers up to date on the latest technologies and best practices, you'll have the support you need to harness AI, streamline processes, and confidently take your next steps.
But, before you decide on a development partner, let's take a look at how AI and ML are influencing fintech, the practical applications your competitors are already using, potential future trends, and how you can build a strategy to use these technologies in your own company.

What is the Role of AI and ML in Fintech?
Artificial intelligence and machine learning in fintech are game-changers.
It processes massive amounts of data about financial transactions at lightning speed, making it easier for financial companies to offer personalized services, assess risks, and automate complex tasks.
Whether it's streamlining customer service through chatbots or enhancing decision-making through data analytics, AI is now a core pillar of financial technology.
Difference Between AI and ML
AI is a broader term used to talk about the ability of a machine to simulate humans, while ML is a subset of that, referring to systems that learn from large datasets.
In theory, machine learning and the large amount of information used in training would help AI produce better results as time passes. In reality, this is not always the case, but in number-heavy industries like fintech, continued improvement is quite promising.
Usually, AI and ML will work together in fintech to create systems that are highly adaptive and evolve based on shifting market conditions.
Key Technologies that Power AI in Fintech
AI-driven biometric authentication, such as facial or voice recognition, adds an additional layer of security, reducing reliance on traditional passwords. This is key in protecting financial data and preventing fraud.
Natural language processing (NLP) is also quite important as it lets chatbots take over low-level HR positions while seeming natural. It also allows users to use technologies like voice commands, increasing accessibility.
Predictive analysis probably provides the most upfront monetary benefit, though. Through machine learning, your fintech software can identify patterns, which then help with everything from customization based on customer behavior to financial forecasts and risk assessments. We'll discuss this further below.
All of this is powered by deep learning, which is one of the many emerging trends in the industry and is seen almost as 'next level' AI with more complex reasoning and more data to refer to than ever before.
How is AI Changing the Financial Industry? Why You Need It
The financial industry has undergone a massive transformation thanks to the power of AI.
For one, automation has reduced the potential for human error and optimized time-consuming processes like loan approvals and fraud detection.
In fact, AI is expected to help banks create more than $140 billion for the banking industry by 2030 through automation and improved efficiency.
The use of AI in finance allows for more precise risk assessments, giving financial institutions deeper insights into market trends and customer behavior.
Not only are the assessments made by AI more accurate and data-driven than ever before, but they're also faster. Humans could never keep up. So, if your competitors are using AI, failing to leverage it will only put you further behind.
AI in fintech markets also supports dynamic pricing models, enabling fintech firms to adjust pricing in real time based on supply, demand, and customer behavior.
This approach is vital in helping fintech companies make maximum profit while maintaining a competitive edge.
Top Use Cases of AI in Fintech
AI has been integrated into various aspects of fintech. Some key applications and use cases for artificial intelligence include:
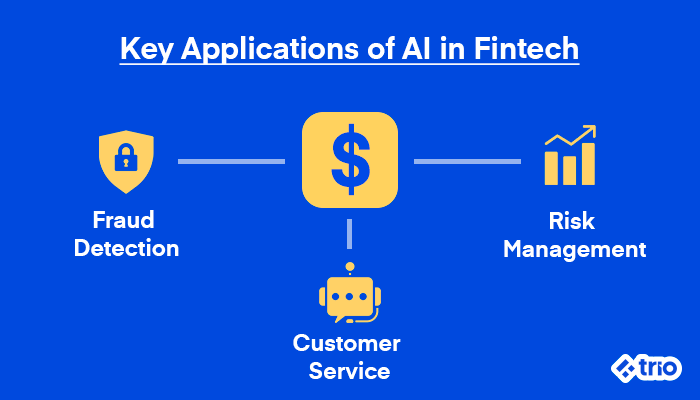
- Fraud Detection: AI can detect unusual transaction patterns and flag fraudulent activities before they happen.
- Customer Interactions: AI-driven chatbots provide 24/7 customer service, helping banks scale their customer support.
- Risk Management: Machine learning models analyze large data sets to provide more accurate risk profiles, improving decision-making processes.
- Algorithmic Trading: AI can process data much faster than human traders, giving institutions a significant edge in making split-second trading decisions.
- Personalized Financial Recommendations: AI analyzes user data, such as transaction history and spending habits, to provide tailored budgeting, saving, and investment options.
- AI-powered micro-investing: Platforms like Acorns and Stash use AI to automate micro-investing, opening up investments to those without large capital reserves.
Fraud Detection
As we have already mentioned above, fraud detection is one of the standout use cases for AI in fintech. PayPal, for example, leverages AI to monitor transactions and detect any suspicious behavior, flagging them for further review.
AI's ability to analyze large data sets in real-time helps banks and financial services detect fraudulent activity the moment it occurs.
And, as companies continue to use these fintech solutions, the vast amounts of financial data that AI and ML technologies can draw from only increase. In theory, this would improve the efficacy of these solutions further.
And, as more and more companies use these fintech solutions, they are able to utilize more data for training and end up becoming even more accurate over time, allowing companies to detect fraud with greater efficiency.
Customer Experience and Virtual Assistants
In our experience here at Trio, one of the simplest examples we often work on would be using advanced AI algorithms to build a chatbot that not only answers a query but also offers tailored financial advice in real-time.
According to Gartner, by 2025, customer experience was predicted to be the key differentiator in financial services, with AI playing a significant role.
Natural language processing, which we have already mentioned above, has allowed these systems to understand even more complex questions and nuanced requests in a tone that is appropriate for the situation. In many cases, users might not even be aware that they are speaking to an AI chatbot at all!
Risk Management and Credit Scoring
Machine learning is a key driver of predictive analytics in fintech, and a major part of the decision-making processes for lending, insurance, and even investment.
By analyzing historical data, machine learning models can identify trends and forecast future outcomes with remarkable accuracy.
This makes AI and ML solutions critical for making objective business decisions that could greatly influence the future of your company.
Think of how AI algorithms can identify a person's creditworthiness and even allocate a number to it based on a standardized credit score to value the risk of lending money to them.
Of course, a person will still need to make the final decision in a lot of cases, but this added information provided through the power of AI and ML can be incredibly useful.
Algorithmic Trading and Investment Management
While it takes humans some time to go over any piece of information and make a decision, which means that the markets are already going to be slightly different when they give their advice, AI doesn't struggle with the same issue.
AI models can detect market fluctuations as they happen, analyze historical movements in less than a second, and in some cases even execute the trade without any human assistance and the associated delays.
AI also does not suffer from issues that may influence human traders, like fear or basic calculation mistakes.
Personalized Financial Recommendations
Similarly, AI can analyze all of a user's spending habits and provide tailored recommendations.
These recommendations can shift as a user's situation shifts.
The issue with these, in our opinion, is that it is difficult to gather data from real life, often leading to unrealistic recommendations for budgeting and similar situations when life suddenly changes. However, the services still offer more sound financial recommendations than many users would ever get without the use of AI.
AI-Powered Micro-Investing
We've already mentioned Acorns and Stash, but these are just the tip of the iceberg. Many apps are trying to make investing easy and less daunting by offering a variety of different ways to allocate money towards investments and savings without the user being affected.
One of the earliest editions of this kind of software involved rounding to the nearest whole amount, saving a couple of cents with each transaction.
With this micro-investing, everyone is able to build wealth, even populations that were previously underserved in this area.
How Do Financial Institutions Leverage AI?
Financial institutions are increasingly using AI to drive efficiency and innovation.
From enhancing customer interactions with virtual assistants to using predictive analytics for investment strategies, AI has become a necessity in today's competitive market.
Retail and Consumer Banking
Wealth management firms, for example, are now employing AI to craft personalized investment portfolios based on customers' financial goals and market conditions.
We've also mentioned how AI chatbots are being used to provide instant responses and answer user questions, minimizing the need for full-time staff to do this work, such as call center employees.
We've also spoken briefly about biometric verification and behavioral analysis. Financial institutions are using these tools for a more customized user experience, but also for improved security.
Lending and Underwriting
Loan applications and approval were previously quite labor-intensive, but now a massive part of these processes, namely creditworthiness decisions, is being handled by AI.
Machine learning models are able to look at all kinds of data, from that traditionally used for credit assessments to alternative data that has not been considered before, to make more accurate decisions.
This not only helps the financial institution but also promotes inclusivity by making lending available to those who do not have a traditional credit score.
Risk and Compliance
AI is also being utilized for anti-money laundering (AML) efforts, detecting suspicious transaction patterns, and ensuring regulatory compliance.
It's able ot pick up on issues instantly, when they would only have been flagged in time-intensive manual audits before.
This technology has made it possible for financial institutions to stay ahead of cybercriminals while also meeting strict regulatory standards.
Benefits of AI and ML in Fintech?
There are many different benefits offered by AI and ML in fintech, from immediate monetary gains to long-term brand reputation. If you are wondering if AI is the right choice for your fintech company, looking at the incredible benefits might make up your mind for you.
Improving Customer Experience
AI-driven solutions allow financial institutions to offer more personalized, faster, and efficient customer service.
AI also helps provide personalized spending insights, recommendations, and savings options, which leads to happier customers and more engaged users and, in turn, greater profits for the fintech business.
Natural language processing and machine learning further enhance customer experience by extracting key information from complex documents like contracts, reducing manual review time for processing vast amounts of financial documentation.
Boosting Profitability and Reducing Operational Costs
AI boosts profitability by automating labor-intensive tasks, reducing operational costs, and improving efficiency.
A report from Accenture predicts that AI could affect up to 73% of the time spent working by bank employees.
With AI and machine learning in fintech handling routine tasks like loan applications, fraud detection, and compliance checks, banks can focus their resources on innovation and growth.
Companies can also use AI and ML to drive operational cost savings by automating Know Your Customer (KYC) procedures, expediting customer onboarding, and ensuring compliance while minimizing errors.
By taking care of all of this on your behalf, AI frees up your teams so that they can focus on other, higher-value work. This allows you to scale faster without needing more employees, further increasing your profitability.
Enhance Financial Products Innovation and Agility
AI takes financial products and services to the next level, allowing fintech companies to provide more innovative, data-driven solutions.
Robo-advisors, for instance, adjust investment strategies in real time based on current market conditions and user preferences, offering a level of service that would be impossible without machine learning.
AI also lets you go through the beginning stages of iteration faster, letting you respond to customer needs while they are still very new and very relevant.
However, in order to make use of AI as efficiently as possible, existing products need to be set up to allow the easy integration of new features for data analytics and machine learning algorithms.
Challenges of AI and ML in Fintech
While there are many great things about using these new technologies in fintech, some unique challenges have also emerged.
In many cases, hiring an unskilled developer to help you integrate AI into your fintech product is a sure way to set yourself up to fall into these traps, while experts are well aware of these issues and others that may be unique to your situation.
Data Privacy and Regulatory Compliance
AI systems handle a lot of sensitive data, bringing it under intense scrutiny. Regulations like GDPR, CCPA, and PCI DSS are starting to crack down on non-compliant AI systems, making compliance essential to the future of your company.
These regulations deal with the storing, sharing, and general use of the data.
The "Black Box" Problem and Explainability
We'll discuss this further in some of the latest trends below, but essentially, it is very difficult to explain how AI makes its decisions.
This means it is very difficult to regulate the use of AI, as you have no idea how it comes to its decisions about customer credit, investment strategies, and fraud investigations.
The issue of this lack of knowledge and explainability has been dubbed the "black box" problem.
Bias in ML
While it seems like AI should make unbiased decisions all the time, this is not the case.
If AI is trained on biased datasets, the AI will be biased. In the cases where AI is continually trained, these issues can crop up without anyone even noticing, leading to unfair lending decisions or inaccurate risk assessments.
Developers need to monitor any tools that they are using constantly so that any biases are picked up early and any potential issues are mitigated.
Cost and Complexity of Implementation
AI only works if it is implemented correctly. The issue is that the expertise required (developers who are both skilled in AI and the fintech industry) is very expensive and in high demand.
There are additional costs related to infrastructure, data engineering, and continued model testing, too. The barrier to entry ends up being quite high.
One great way to mitigate costs is to hire nearshore or offshore developers who specialize in fintech and are familiar with the US regulatory landscape. At Trio, we provide these developers to clients, going a step further by ensuring the developers have worked on similar projects to yours before.
Emerging Trends in AI and Fintech
With so many people adopting the use of AI, it is only natural that the landscape is constantly shifting. From the use of generative AI to concerns about regulatory compliance and ethical use, there are some emerging trends you should be aware of.
Generative AI in Financial Services
Generative AI opens up new opportunities for personalized financial advice. Imagine a future where AI could craft a detailed financial strategy based on your spending habits, financial goals, and market conditions.
This type of service would allow more individuals to gain access to high-quality, tailored financial guidance, helping to bridge the financial literacy gap.
If you aren't sure where to start, we recommend making use of a chatbot to answer some of the most common questions your customer service agents may get. This has become pretty much industry standard at this point.
You could also use generative AI for your internal reports and documents.
Agentic AI and Autonomous Finance
Agentic AI is the next big thing. It is relatively similar to some of the other AI models on the market at the moment, but requires human input to set in motion a chain of events, allowing it to manage tasks on a user's behalf. This could be a major breakthrough in portfolio or budget adjustment going forward.
The shift to agentic AI and autonomous finance will allow companies to move from reactive to proactive technology. The opportunities are boundless if you have the right developers on your team who can help you use these technologies to scale.
AI and Blockchain
Another trend is AI and blockchain being used together in an effort to create financial systems that are more secure and transparent, offering features like automated smart contracts to users.
These systems are also able to reduce costs when making cross-border payments and automate regulatory documentation, risk flagging, and a variety of other things.
Explainable AI (XAI) and Ethical AI
Fintech is just one of the many high-stakes fields in which AI and ML are now being used. Healthcare, education, and maintenance are also experiencing more and more AI integration, leading to a growing concern about how these systems work. The "black box" nature of AI becomes a major problem here.
To address this, a lot of fintechs are investing in explainable AI, which can be audited by humans.
The result has been an increase in trust amongst regulators and users.
AI in Regulatory Compliance
AI needs to be regulated, but it can also be a helpful tool in the regulatory process in general. It is being used to manage complex compliance requirements, doing everything from transaction monitoring to automated reporting.
The result has been that companies are able to scale far more easily than they have ever been able to before.
How Fintech Startups Can Use AI
AI's influence on the financial sector is only expected to grow. The hope is that it will only lead to improvements, but it is also likely that some issues will come up, as with all new technologies.
AI's evolution will continue to reshape how financial services operate, driving efficiencies, enhancing customer experience, and opening up new market opportunities.
For startups, AI integration can be a game-changer, but it's not always easy to figure out where to start.
Building AI solutions requires specialized skills that many small teams simply don't have in-house.
This is where the right partnership makes all the difference.
Outsourcing to a development partner like Trio gives startups access to experienced developers familiar with both fintech app development and effective client communication.
By embracing AI now, you can position your company at the forefront of financial innovation. Reach out to us with more information on your requirements so we can get you started with collaborative software development.